In short
- Cloudflare accused Perplexity AI of utilizing “stealth crawlers” to evade bans, rotating IP addresses and mimicking common browsers to entry blocked web sites.
- Cloudflare delisted Perplexity from its verified bots program and deployed new technical defenses to catch and block misleading scraping.
- Perplexity denies the claims, calling Cloudflare’s proof a “gross sales pitch” and disputing that any banned content material was accessed.
Perplexity’s crawlers stored accessing content material from tens of hundreds of internet sites even after these websites explicitly blocked them, in response to web infrastructure supplier Cloudflare. The corporate mentioned Monday it had delisted Perplexity from its verified bot program and applied blocks in opposition to what it characterised as misleading scraping practices.
San Francisco-based Perplexity was based in 2022 by Aravind Srinivas (CEO, former OpenAI researcher), Denis Yarats (former Fb AI), Johnny Ho, and Andy Konwinski (co‑founders of Databricks). The corporate has acquired funding from buyers together with Elad Gil, Nat Friedman (former GitHub CEO), and Nvidia, amongst others, and was valued at $18 billion after elevating $100 million final month.
The current battle erupted after Cloudflare prospects complained that Perplexity was nonetheless scraping their websites regardless of implementing each robots.txt directives and particular firewall guidelines to dam the AI firm’s declared crawlers. Cloudflare engineers Gabriel Corral, Vaibhav Singhal, Brian Mitchell, and Reid Tatoris confirmed in exams that “Perplexity’s crawlers have been the truth is being blocked on the precise pages in query.”
To check Perplexity’s conduct, Cloudflare created a number of newly bought domains with restrictive robots.txt recordsdata that prohibited all automated entry. “We carried out an experiment by querying Perplexity AI with questions on these domains, and found Perplexity was nonetheless offering detailed info concerning the precise content material hosted on every of those restricted domains.”
What occurred subsequent stunned them. Reasonably than respecting the blocks, Perplexity appeared to change techniques. “We noticed that Perplexity makes use of not solely their declared user-agent, but in addition a generic browser supposed to impersonate Google Chrome on macOS when their declared crawler was blocked,” the engineers wrote.
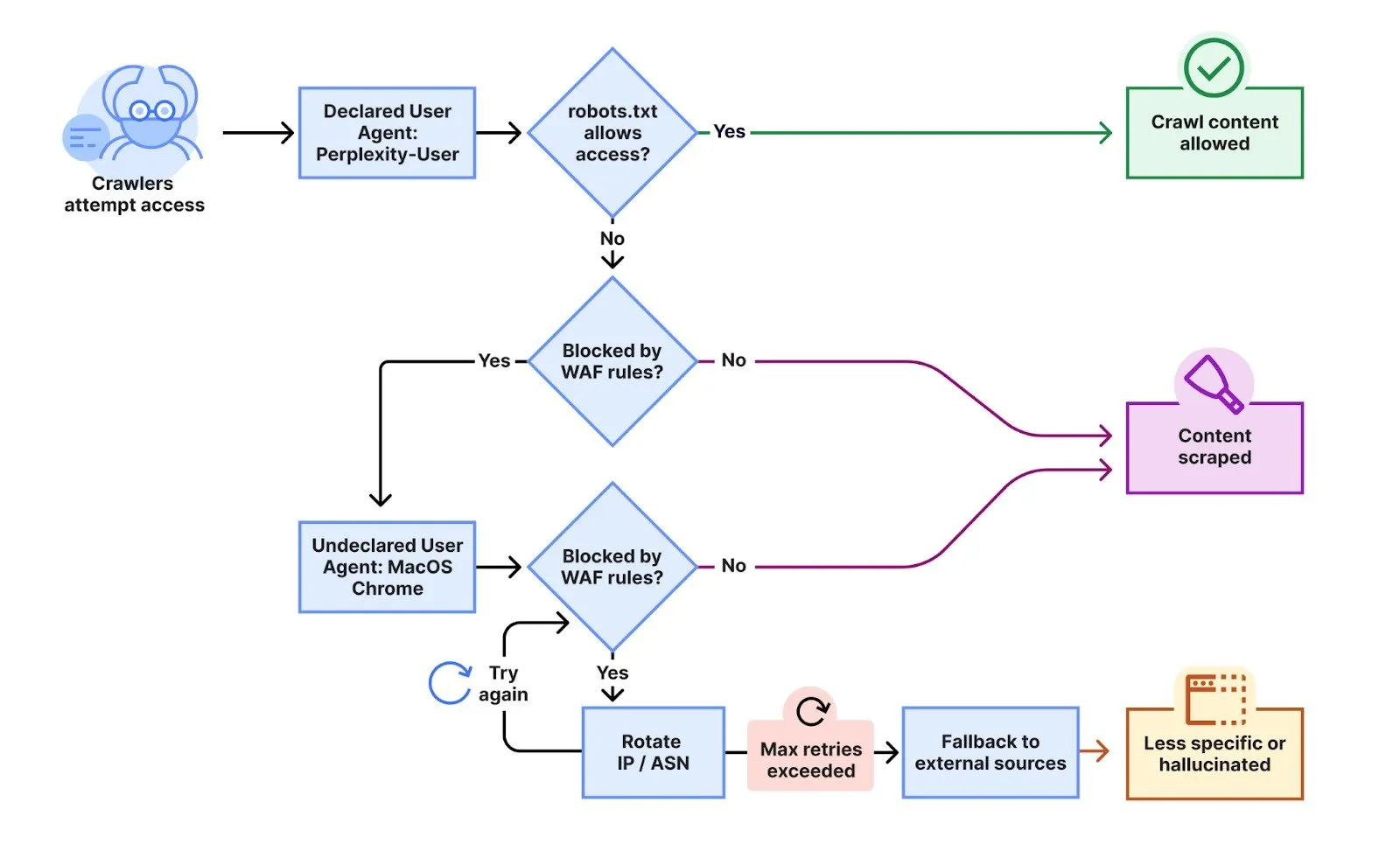
The stealth crawlers employed subtle evasion strategies. “This undeclared crawler utilized a number of IPs not listed in Perplexity’s official IP vary, and would rotate by way of these IPs in response to the restrictive robots.txt coverage and block from Cloudflare. Along with rotating IPs, we noticed requests coming from totally different ASNs in makes an attempt to additional evade web site blocks.”
In response to Cloudflare, Perplexity’s “declared” crawlers—those which are simply identifiable—generate 20-25 million requests each day, whereas the undeclared stealth crawlers—these which depend on shady techniques to cover their objective—add one other 3-6 million requests per day. “This exercise was noticed throughout tens of hundreds of domains and thousands and thousands of requests per day.”
The corporate didn’t reply to Decrypt‘s request for remark. A spokesman dismissed the allegations to TechCrunch as nothing greater than a Cloudflare “gross sales pitch.”
Cloudflare CEO Matthew Prince has been vocal about what he sees as AI corporations’ unsustainable extraction of internet content material. “Search visitors referrals have plummeted as folks more and more depend on AI summaries.” In July, he revealed devastating ratios: whereas Google sends one customer for each 18 pages it crawls, AI corporations are far worse. OpenAI’s ratio deteriorated from 250-to-1 six months in the past to 1,500-to-1 at this time. Anthropic’s numbers are much more excessive, leaping from 6,000-to-1 to 60,000-to-1 in the identical interval.

This prompted Cloudflare to launch what it calls “Content material Independence Day,” defaulting to blocking AI crawlers for all new domains, changing into the de-facto vigilante defending content material creators from the threats of pesky AI crawlers.
As Decrypt beforehand reported, greater than 1,000,000 web sites had already opted into blocking since final fall, with main publishers together with the Related Press, Time, The Atlantic, BuzzFeed, Reddit, Quora, and Common Music Group becoming a member of the motion.
“There are clear preferences that crawlers ought to be clear, serve a transparent objective, carry out a selected exercise, and, most significantly, comply with web site directives and preferences,” Cloudflare said. The corporate contrasted Perplexity’s conduct with OpenAI, which it mentioned correctly respects robots.txt recordsdata and stops crawling when blocked.
Cloudflare’s response consists of each quick technical measures and longer-term initiatives. The corporate has deployed signature matches for the stealth crawler into its managed guidelines, obtainable to all prospects together with free customers. It is also creating instruments like an “AI Labyrinth,” which traps non-compliant bots in mazes of faux content material, and a “pay-per-crawl” market that might enable publishers to cost AI corporations for entry to their content material.
Usually Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.