Two American AI labs launched open-source fashions this week, every taking dramatically totally different approaches to the identical drawback: the way to compete with China’s dominance in publicly accessible AI techniques.
Deep Cogito dropped Cogito v2.1, an enormous 671-billion-parameter mannequin that its founder, Drishan Arora, calls “the perfect open-weight LLM by a U.S. firm.”
Not so quick, countered The Allen Institute for AI, which simply dropped Olmo 3, billing it as “the perfect totally open base mannequin.” Olmo 3 boasts full transparency, together with its coaching knowledge and code.
Paradoxically, Deep Cognito’s flagship mannequin is constructed on a Chinese language basis. Arora acknowledged on X that Cogito v2.1 “forks off the open-licensed Deepseek base mannequin from November 2024.”
That sparked some criticism and even debate about whether or not fine-tuning a Chinese language mannequin counts as American AI development, or whether or not it simply proves how far U.S. labs have fallen behind.
> greatest open-weight LLM by a US firm
that is cool however i’m undecided about emphasizing the “US” half because the base mannequin is deepseek V3 https://t.co/SfD3dR5OOy
— elie (@eliebakouch) November 19, 2025
Regardless, the effectivity beneficial properties Cogito reveals over DeepSeek are actual.
Deep Cognito claims Cogito v2.1 produces 60% shorter reasoning chains than DeepSeek R1 whereas sustaining aggressive efficiency.
Utilizing what Arora calls “Iterated Distillation and Amplification”—instructing fashions to develop higher instinct by self-improvement loops—the startup educated its mannequin in a mere 75 days on infrastructure from RunPod and Nebius.
If the benchmarks are true, this may be probably the most highly effective open-source LLM at present maintained by a U.S. group.
Why it issues
To this point, China has been setting the tempo in open-source AI, and U.S. corporations more and more rely—quietly or brazenly—on Chinese language base fashions to remain aggressive.
That dynamic is dangerous. If Chinese language labs change into the default plumbing for open AI worldwide, U.S. startups lose technical independence, bargaining energy, and the flexibility to form business requirements.
Open-weight AI determines who controls the uncooked fashions that each downstream product relies on.
Proper now, Chinese language open-source fashions (DeepSeek, Qwen, Kimi, MiniMax) dominate international adoption as a result of they’re low-cost, quick, extremely environment friendly, and continually up to date.
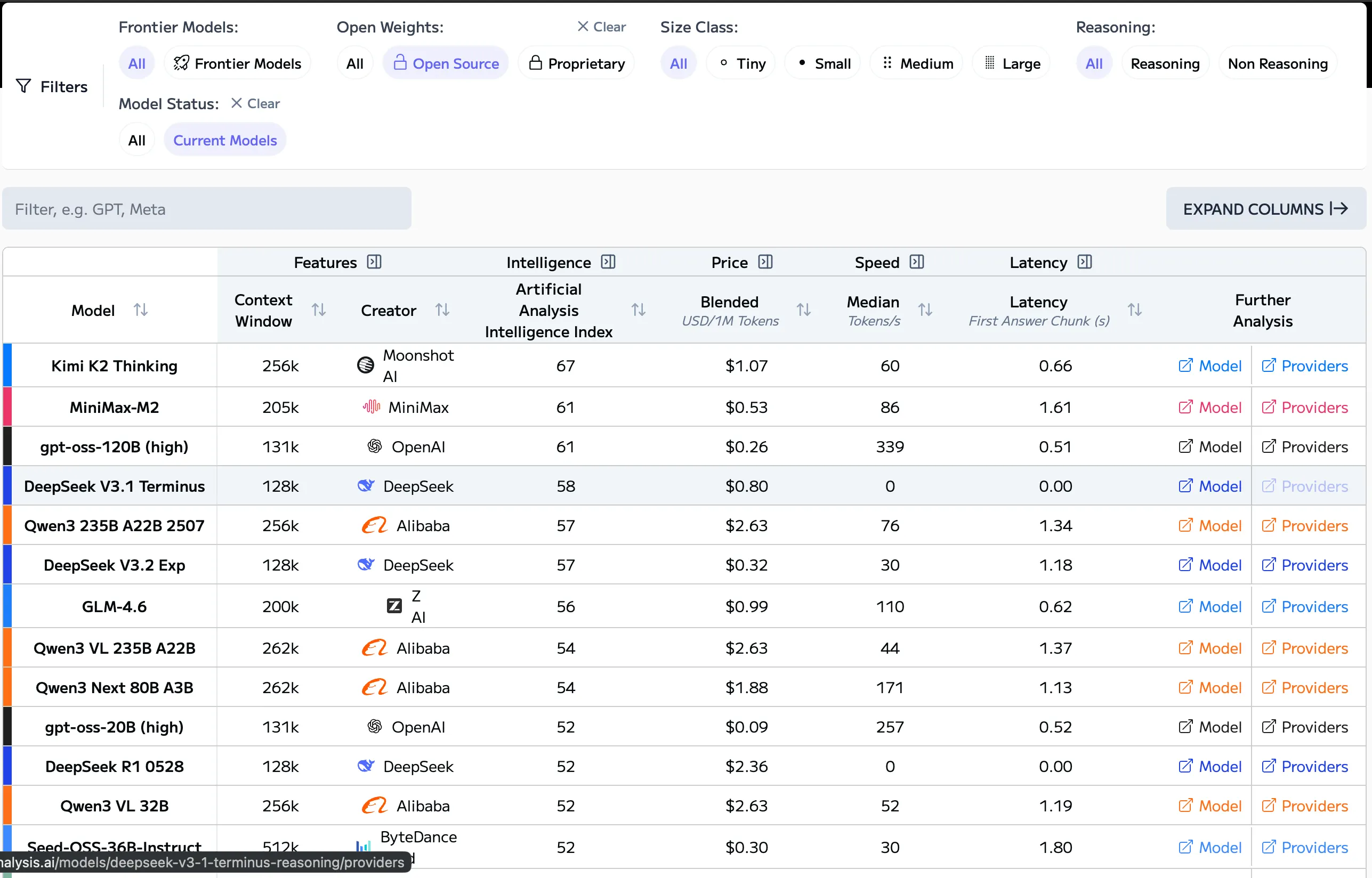
Many U.S. startups already construct on them, even once they publicly keep away from admitting it.
Meaning U.S. companies are constructing companies on prime of overseas mental property, overseas coaching pipelines, and overseas {hardware} optimizations. Strategically, that places America in the identical place it as soon as confronted with semiconductor fabrication: more and more depending on another person’s provide chain.
Deep Cogito’s strategy—ranging from a DeepSeek fork—reveals the upside (fast iteration) and the draw back (dependency).
The Allen Institute’s strategy—constructing Olmo 3 with full transparency—reveals the choice: if the U.S. desires open AI management, it has to rebuild the stack itself, from knowledge to coaching recipes to checkpoints. That’s labor-intensive and sluggish, nevertheless it preserves sovereignty over the underlying know-how.
In principle, in the event you already appreciated DeepSeek and use it on-line, Cogito offers you higher solutions more often than not. In the event you use it through API, you’ll be twice as glad, because you’ll pay much less cash to generate good replies because of its effectivity beneficial properties.
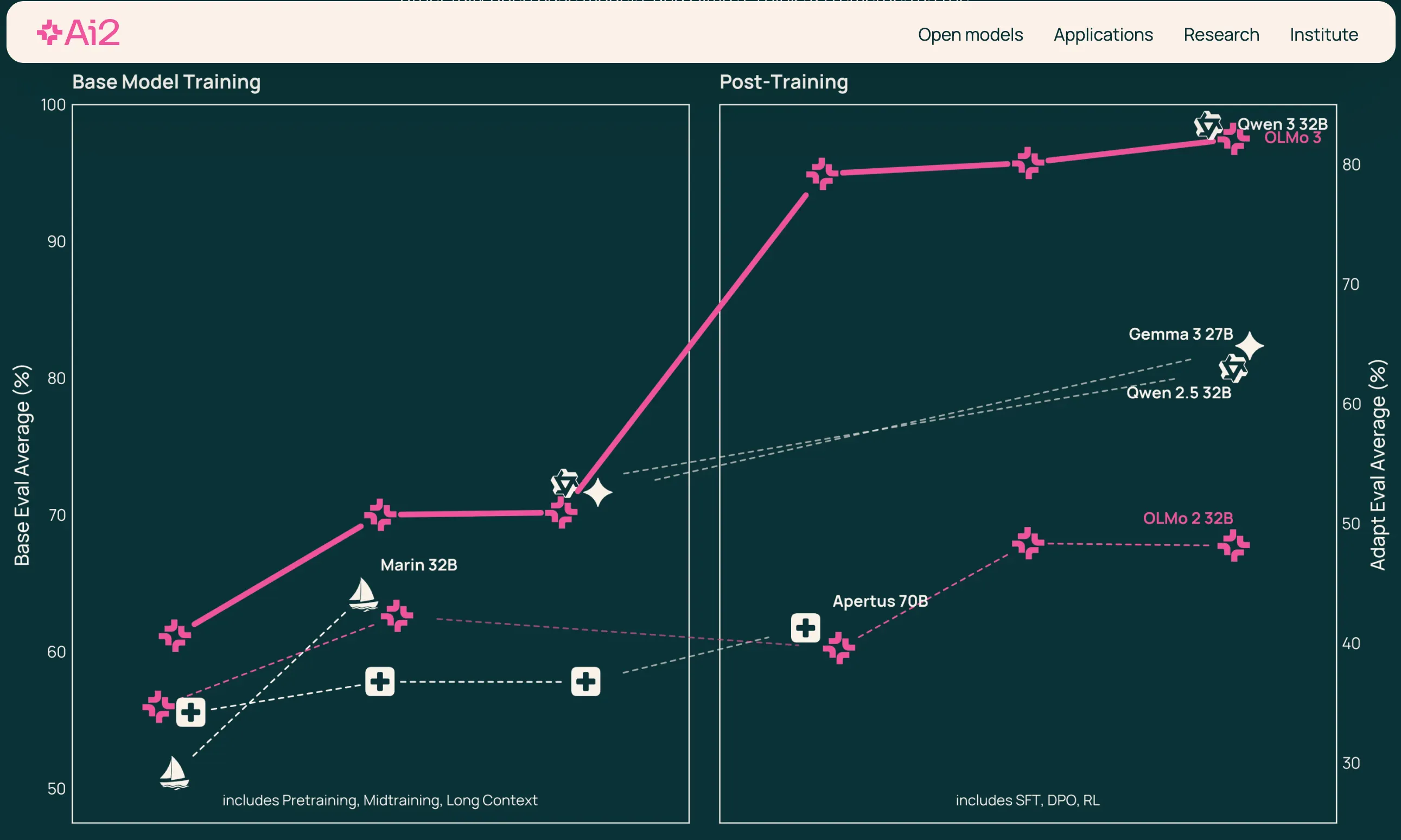
The Allen Institute took the alternative tack. The entire household of Olmo 3 fashions arrives with Dolma 3, a 5.9-trillion-token coaching dataset constructed from scratch, plus full code, recipes, and checkpoints from each coaching stage.
The nonprofit launched three mannequin variants—Base, Suppose, and Instruct—with 7 billion and 32 billion parameters.
“True openness in AI is not nearly entry—it is about belief, accountability, and shared progress,” the institute wrote.
Olmo 3-Suppose 32B is the primary totally open-reasoning mannequin at that scale, educated on roughly one-sixth the tokens of comparable fashions like Qwen 3, whereas reaching aggressive efficiency.
Deep Cognito secured $13 million in seed funding led by Benchmark in August. The startup plans to launch frontier fashions as much as 671 billion parameters educated on “considerably extra compute with higher datasets.”
In the meantime, Nvidia backed Olmo 3’s improvement, with vp Kari Briski calling it important for “builders to scale AI with open, U.S.-built fashions.”
The institute educated on Google Cloud’s H100 GPU clusters, reaching 2.5 instances much less compute necessities than Meta’s Llama 3.1 8B
Cogito v2.1 is out there at no cost on-line testing right here. The mannequin might be downloaded right here, however beware: it requires a really highly effective card to run.
Olmo is out there for testing right here. The fashions might be downloaded right here. These ones are extra consumer-friendly, relying on which one you select.
Usually Clever Publication
A weekly AI journey narrated by Gen, a generative AI mannequin.